

Ijraset Journal For Research in Applied Science and Engineering Technology
Realtime Accent Translation
Authors: V A Mayavathi, Ballani Vignesh, V. Hemavathi, Aditi Gupta, K. Gnanendra Varma, Dr. Galiveeti Poornima
DOI Link: https://doi.org/10.22214/ijraset.2025.66549
Certificate: View Certificate
Abstract
Accent Translation in Real-Time is one of the very first projects meant to overcome the barriers erected by regional accents in spoken languages. It uses the state-of-the-art research on speech recognition, NLP, and speech synthesis while translating speech from a source accent into a neutral or target accent in real-time. Accent detection and modification may include the use of deep learning models, like RNNs or transformers. In addition to the regional phonetic features, audio inputs on words with contextual meanings allow the reconstruction of the speech to conserve a desirable accent and continue giving the speaker their identity. Global communication, educational, and accessible applications would cultivate effective, comforting communication, where care for lingual background goes by the board. Project scope: low latency processing and scalability-which should be able to support many languages and varieties of accents that might make it extremely practical yet quite an effective tool in this increasing world. Keywords— Real-Time Accent Translation, Speech Recognition, Natural Language Processing (NLP), Speech Synthesis, Deep Learning, Transformers, Multilingual Support, Low Latency Processing, Accent Identification, Phonetic Mapping, Seq2SeqModels, Voice Synthesis, Ethical Considerations, Global Communication, Accessibility
Introduction
I. INTRODUCTION
Therefore, as third world progress into miles and miles of various linguistic and cultural bases, the urge to communicate spreads along with this proportion. Though there is a number of unimaginable accent like sounds created in human speech about language, that stretches its vast horizon by expanding more complexity in the way toward smooth communication. In short, in real-time accent translation, all the obstacles which have been created between two human beings thereby unlock fruitful talks among them both on earth.
Geographically, culturally, and linguistically are the major elements of the accent. This has to cut down very deep into all parts and divisions of working places like schools and more. For instance, if it would have spoken with influential words then above than one wouldn't have listened to it as the intensity in correlation with the level with accent was of such kind or power by which that employee never crossed so therefore the statement went unheard and coordination wasn't taking place among the staff employees. It has to be that spoken term where it will act as an environment that is more effective at a lower cost.
This is a deep model summary of NLP and speech recognition. Some of the local phonic features are used and applied as a neutral accent or target accent in order to hold agglutinate a person's identity while at the end of that cycle and not too far from making a partnership with time nearly level is just that fluidity of sound-just keeps moving doesn't cause even so much as to twitch at most when some disagreement comes into consideration, at any rate for the purposes of using it in dialogue it will finish without allowing or giving any such place, much less room to interlude.
Now, this technical frame is pieced together below. That contains a minimum number of key elements that enable real-time accent translation. Words of speech get caught up with transcription forwarded into a machine learning component that would actually identify the speaker's accent and do a much better meaningful contextual translation while carrying it out. Finally, it composes the sound output with all intonations of the speaker in the required accent. Thus, the scope of translating real-time from some accent into the other stands at the vast scope used in every sphere of life. Thus, it has now become quite easy to communicate in this global business world as well as the multilingual world for international communication of ideas. This also rules out customer care as all of them hail from a different lingual background. Technology accelerates learning. This simply means that both the learner as well as the teacher enjoy free flowing conversation hassle free and language. And it is possible through this medium in a more fluid and lesser-placed way to phrase the native speaker with which one wants to be heard with clearer and without ambiguity.
Perhaps one of the greatest inventions comes out of the sphere of real-time accent translation on earth, but actually developing it might be really quite hard. Really high computation needs, mixed or hybrid accent somewhat posing like kind of a problem, concerns related to ethics questions related to linguistic identity works emerge as a serious issue.
No shadow of a doubt in life, of course faithful to real-time accents translation and such technology, including applied machine learning that comes together with bigger capacity, especially being multilingual by ability that it is increased to be augmented while virtual reality on applied technology all in human communication exchange. After all, it may connect much of the accents to communication much better than ever before; there comes in there much just world society free of language-related barriers. For basically, it is really a bridge to common understanding and ratio.
II. RELATED WORK
The field of real-time accent translation is marked by a synergy of technological advancements in speech recognition, natural language processing, and speech synthesis. Initial research efforts concentrated on enhancing speech recognition systems' performance for both native and non-native speakers, revealing significant challenges due to accent-induced phonetic variability. The deployment of deep neural networks, particularly those employing acoustic modeling, has been pivotal in improving recognition accuracy across diverse linguistic profiles.
Contemporary research has pivoted towards leveraging transfer learning to refine speech recognition models, enabling them to adapt to new accents with minimal data. This strategy enhances the models' capability to generalize, ensuring robust performance even with limited exposure to specific accent datasets. Studies have also explored the integration of phoneme-level recognition to address the nuances of accent variation more effectively, highlighting the growing importance of fine-grained linguistic features in accent translation tasks. In accent adaptation, recent innovations have introduced methods like domain adversarial training and zero-shot learning, which empower systems to process previously unseen accents effectively. These advancements are critical for democratizing access to accent translation technologies, making them more universally applicable and inclusive. Additionally, unsupervised learning approaches are increasingly being explored to overcome the reliance on large, labeled datasets for accent recognition, reducing the barrier to entry for developing diverse accent models.
The speech synthesis frontier has been transformed by models such as Tactron and Wave Net, which produce highly realistic and natural-sounding speech. These technologies are essential for generating authentic accent translations that maintain the speaker's unique voice characteristics and emotional expression. Recent efforts have focused on extending these models to allow for more fine-tuned control over the synthesis, such as adjusting the degree of accent transfer or preserving emotional tone.
Despite these advancements, real-time accent translation continues to grapple with challenges, particularly in low-latency processing and the ethical implications of linguistic standardization. In real-time systems, minimizing delay while ensuring high accuracy and intelligibility is a critical hurdle. Furthermore, questions surrounding the preservation of linguistic diversity and the potential for cultural erasure have led to calls for more inclusive and culturally sensitive translation frameworks. Researchers are increasingly focusing on balancing technological progress with ethical considerations, aiming to create systems that respect the unique aspects of different accents and dialects. Ongoing research endeavors aim to address these issues by optimizing algorithms for real-time performance and embedding cultural sensitivity into technological frameworks. This includes exploring techniques for accent preservation, where the goal is not merely to translate but to maintain the rich cultural context associated with each accent. Additionally, the role of user-centric design in real-time accent translation systems is gaining prominence, ensuring that these technologies serve diverse user bases with varied linguistic backgrounds.
In summary, the evolution of real-time accent translation embodies the convergence of cutting-edge speech technology and ethical considerations. As the field progresses, it holds the potential to revolutionize global communication, fostering a more inclusive and interconnected world. The future of accent translation lies in its ability to bridge linguistic and cultural divides while empowering individuals to communicate seamlessly across diverse linguistic landscapes.
III. PROPOSED SYSTEM
This paper describes the pioneering accent-to-voice transcription system targeted for seamless spontaneous conversations without major interdependence hindrances to speaker interaction of different accents speaking different languages. In reality, the essence on both ends had been transcended at Sub-latencies so as the language and hence linguistic features would be efficiently and completely streamed without losing significant bits of any constituent. It is from the integration of current speech recognition, natural language processing, and speech synthesis technologies that the system is accurate and efficient for real-time applications.
An advanced system more specifically based on advanced deep learning techniques, such as the concept of transfer and domain adaptation in learning strategies overcoming variabilities between accents. The system will train strong models on large datasets that comprise a diversification of accent profiles to discern and translate the accents differentiated by background in languages.
Such methods will be further advanced in adversarial training, zero-shot learning, and multi-task learning, of whose performances need to be optimized crossing a broad range of unseen accents. Magic in that system is the way it embeds a quite good-quality speech synthesis engine that produces fluent, natural-sounding translations and retains the prosodic features characteristic of the speaker.
This system will be a low-latency process; hence it will ensure that the real-time performance of the system and the communication process would be very smooth without such a delay. Cultural awareness and preservation of accents will be important things while designing this system; the translation that would be done by this system would respect all those forms and aspects that would reflect the richness of human accents. This is how the proposed workflow of the real-time accent translation system could actually be divided into steps, really focusing on accuracy, speed, and cultural importance. Here's the flow:
Speech Input (User 1)
Accent Recognition & Analysis
Accent Translation (User 1 to User 2)
Text-to-Speech Generation
Real-Time Output (User 2)
Bidirectional Translation (Optional)
IV. METHODOLOGIES
Overview of the System
This is because the real-time accent translation system means that one can be fluent in the languages and tones in which to communicate. Then there is written form, like said aloud; that gets translated into text, then turns to the desired accent of the speaker. That means it transmutes to speech, thus a way of correct communication. Thus, one bridged most gaps that exist because of communication, which is mostly found in the environment the most multilingual scenes are placed-international conferences as well as other travels cross different cultures and business, etc. There are three major processes of the system: speech recognition, translation and text-to-speech synthesis. All bring the users' real-time translation and pronunciation of spoken content. Thus, it allows having users speak in their mother tongue accent. Further, it supports a bidirectional conversation wherein one can speak aloud in a foreign language and then read what was spoken in another or a different accent/voice. In that regard, it suits better conversations in multiple languages.
- Voice recognition: It's a part of the system; this is recording through an audio feed coming from advanced voice recognition-an audio feed with recording by the microphone, taking the voice going through audio processing to translate words spoken into those said, process by the voice recognition engine like Google Speech-to-Text API, capturing of live speech into text. This system also possesses a noise cancellation property regarding this process of cancelling the background noises; hence no interference to the input speech signal. Then the loss in terms of accuracy with regard to transcription can be one of its significant effects.
- As the machine is already provided with the translation text of the speech, the machine will start with that translation in a language chosen and preferred by the users to fit in with their demands. It should use a translation API wherein, in other languages, it installs Google Translate. From there, it will allow the user to type whatever preference they want in their favorite choice of language, whether it be English-that is, US, UK, or Indian; Hindi; Telugu; and Kannada. This is the translation that takes the word from a native speaker of the original speaking and translates it into an actual word of the accent desired.
- Text-to-speech synthesis-After translation the TTS reconverts that translated text in speech. A text-to-speech engine that is what, the gTTS library Google does, thereby making words talk with the chosen accent or chosen language. As such, on receiving the message, the one will hear its translation in chosen accent or the chosen language.
The first one is the target language or accent. Then the system hears speech, transcribes it to text, and later translates what it had gotten into the required language before finally converting it to speech. Last is playing it out on the translated speech by its audio output. It is dynamic and is always on the look-out for fresh speech input; it also brings about real-time communication It does not stop in one place but goes into the loop, scanning for new inputs: speech coming into the language processing system as well as processed translation and again translated speech produced out of that. Therefore it makes possible lively conversation in time without waiting over the processing times to be crossed. Real-time interaction is essentially necessary when bringing a naturalist spontaneity in cross-language communicating. All of these can be brought together into one coherent system, thereby giving an effective solution toward multilingual communications.
Whether it is a tourist in some other country, an office worker working together with colleagues in some other region, or any other such person who may require live translations, the systems work perfectly to eliminate any given barrier in some other language.
It supports more than one accent, thus allowing the speaker to speak with a natural accent while working on some other language and in this way, the experience continues to be personable and culture-sensitive. This is the most critical part of the process because, in the future, the world will always continue interlinking, and this is just a stepping stone in the development of very advanced, interactive tools that can cope with complex, dynamic conversations in different languages and accents, which would really get people talking beyond language and cultural barriers properly.
V. SYSTEM ARCHITECTURE
It will genuinely be in real-time translating speech with legitimacy that may allow it to pick up many other forms of accent and dialects. All work-related components with it are in order; speech recognition, translation, and text-to-speech-all is well-integrated so that all fits together in a fine user experience.It will record input audio on a virtual device such as VB-Cable with real-time stream assured by pyaudio. This would adjust the actual real time of the ambient sounds such that the recognition of speech is improved. Further recognitions will also be accurate. Accent and language would not matter with this feature of Google Speech API given by the library for recognizing speech. There are text-based options for the user for every accent or a preferred language with which he's speaking with it. Such a preselected option would be mapped with predefined dictionaries along with the corresponding language codes in such a way that it would process as per whatever preferences the users might want. The Google Trans library, which has been built while taking the help of the Google Translate API, would allow for the translation of identified text into a target language based on the preference of the users. This would thus advance solid evidence toward the quality of such languages like Hindi, Telugu, and Kannada. These would henceforth be used in synthesis speech.This would thus demand gTTS, Google's Text-to-Speech. Translates text into an audio translation. It can even take the text converted to resemble an audio presentation. Thus, it will thereby leave a system to provide sound output but coherently.It uses pygame while playing the actual sound itself and sends synthetic audio back through for listening; on top of all that, it has very strong capabilities for cashing efficiently onto temp files without polluting up its resources; so after clean and tidy mode cleanup.It will deal with the mechanisms of error quite strongly because it will overcome the issues such as recognition timeouts and failures of API requests. Thus, it will be dependable and user-friendly. Further, it will advance by making further improvement with the help of newer models of speech recognition that further helps access through mobile and web interfaces.It will honestly be in real time translating speech with legitimacy that may allow it to pick many other forms of accents and dialects. All the work components necessary to achieve all this are well in place: speech recognition, translation, text-to-speech-all well integrated so all fits together in a fine user experience.It will capture the audio input by using VB-Cable-a virtual audio device-and test whether it captures the real-time audio stream from pyaudio. Real-time adjustment for the ambient noise is ensured, so that optimum speech recognition can be achieved with good recognition rates inside the system. Accent or language will no longer be an issue because Google Speech API will also be employed to be implemented in the speech recognition library. For each accent or language chosen, the user does text-based selection in order to speak to it. The prechosen options are matched to the relevant language codes of predefined dictionaries in order for anything favored by the users to be processed accordingly. The text recognized will thus be translated to the chosen target language in support for such beautiful languages, such as Hindi, Telugu, Kannada, and such a long list goes on. This translation, being implemented, automatically means an incredibly vivid form of support towards those beautiful languages-only a few examples in course, with many more, to boot. So, such translation is put into effect. Thus, it speaks
.It makes use of gTTS, or Google Text-to-Speech. It is the text-to-speech transformation wherein the translated text is transformed to an audio file. It would even produce even more natural and coherent audio outputs since it is going to go through the computation of a fitting language or accent to be utilized.It was playing audio using pygame. And it was giving synthesized audio to the user so that he could hear it. It cached highly efficiently in the form of temp files, cleaned its place after it's played without wastage through fairly just mechanisms which did not waste resources optimally either.
Mechanism of error- It will overcome common issues relating to recognition, such as recognizing timeouts and a failure of an API request.Thus, reliable and user-friendly. Further advancing with new models of improvements in speech recognition that further provide access through a mobile and a web interface also.

Visual Block diagram
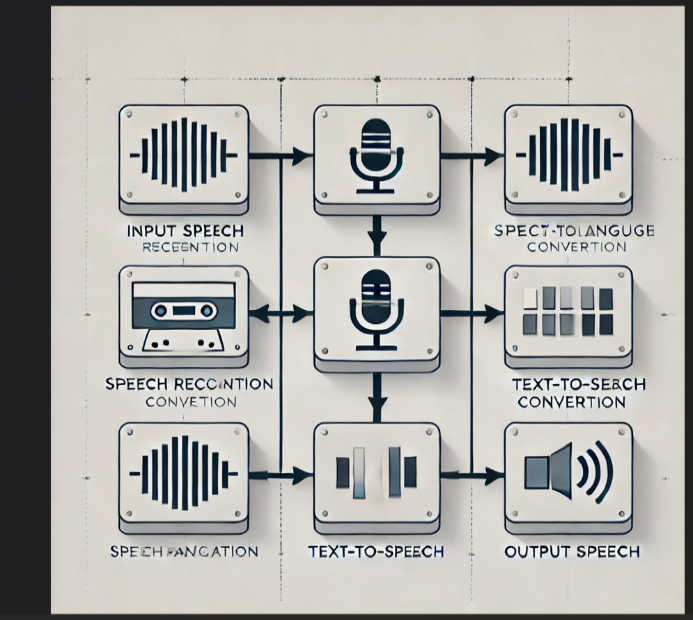
VI. CORE TECHNOLOGIES AND ALGORITHMS
This has called for the simplest elements, namely those technologies that need to be demonstrated to depict major issues with algorithms relevant to accent interpretation in real time and the resulting standard one as given above. This would facilitate cross-lingual and cross-accental communication because of its availability of simultaneous speech recognition, language translation, and synthesis of text into speech. One further relies much on various other libraries and APIs for working. It achieves this by transcribing the real-time input audio during the process. So in that case, a result needs to be returned back as an audio file.
1) Speech Recognition: This literally means that this software would have recognized words and phrases, directly in terms of speech format translated into words. Applications below depend considerably on an astonishingly helpful library offered by Python called Speech Recognition. In the speech recognition comes Google proprietary speech API that would get it pretty well into decoding speech patterns, clear enough within the terms and the turning over to words practically real-time.
- Key Features of Speech Recognition: Audio Input through the Microphone It employs noisy speech by human beings because it receives audio inputs mainly through implementation by VB-Cable and therefore converts it into an output device that serves as making virtual audio inputs.
- Noise Compensation: Compensations also of ambient background noise and list of features includes its containing the action known as adjust_for_ambient_noise, used further to enhance recognition accuracy in noisier environments. So, in effect, this will get recognizer to adapt all the more amenable to variations in noise conditions so as to reach maximum possible accuracy in noisier as well as considerable quieter environments as well. Recognition Algorithm: Audio data recording-accepts through this speech recognition API that modify audio data to these text formats of wave sound pattern understood on how to correspond to these series of representations or models as they are used in the linguistics system so those will predict certain words in their prediction on the way the generation would look alike it in its actual sentence pronounciation.
2) Language Translation: This does a transcription of the speech, thus transforming the text known into any language preferred in text translation. For this purpose, the function google trans had to be utilized in my code. Guess it is also the Python API wrapper for the Google Translate application. Translation uses
- Text Input: In doing this step the translation algorithm which are recovered from texts found during speech recognition.
- Translation Algorithm: it uses free translation that is back from statistical models and a Neural machine translation technique with massive passing through of data for the two language pairs as a way of ensuring a precise mapping between source language and target language. Apparently, Google trans translates more than 100 dialects spoken within regional accents that include; the United States and The United Kingdom as well as those of Republic of India and these languages consist of; Hindi, Telugu and Kannada.
- Personalization: it will ensure that all those rights are bestowed upon one page for this person concerned through this product which can translate any language into some other desired as if exactly fulfilling the exact whim of one and only wish concerning dialect accent also.
3) Text-to-speech Synthesis: This is supposed to have the voice through the text but instead brings up a reverse translation-it translates a portion of text into speech. It feeds upon the same text fed in, constructing translated text as some type of natural feeding algorithm. It's being used through the TTS API in Google in collaboration with gTTS as programmed, so its run ended up. The Stages for TTS-The TTS translates the input texts to what level. Google TTS speech synthesis algorithm scans through the texts used in creating the words and phrases that can then synthesize inputs via those texts. It then synthesizes by using the sounds on its speech through sequence phonetics, hence making one develop excellent deep learning in fantastic datasets of such synthetic human voices, naturally put together.
- Voice Personalization: The user can choose the accent or the language through which the voice is to be generated. The gTTS library supports almost all languages that express their respective accents; therefore it has made its output more or less flexible as per the requirement of the client. This program would itself talk within US English, British English, Indian English, Hindi, Telugu, and Kannada along with numerous varieties of problems.
4) Audio Play again and Control: The other section at the tail end of the system has a section for audio output. This loads the audio file which it requires to give out the speech. Then, through a library of py game it plays the audio in such a way that it gives an illusion of real time output.
- Steps: Once it reads a text as speech, it saves that to file in.mp3 format. It gives some unique name to the file so that already generated files would not get over-written. Playback Algorithm This module, py game. mixer would be used to load that audio file which could play. That quality of play of audio is fine. That can keep on listening for new inputs whenever it proceeds with audio asynchronously. It removes temporary files according to the plays of audio of the system and also consumes disk space for free purposes; it removes every type of temporary. mp3 also created in the time period of play.
5) Exception Handling and Optimization of the system This must have been the real-time processing system that could have thrown so many errors and exceptions that might have arisen in the given system. It has conquered all major ones that were
- Speech recognition errors: System doesn't hear; thus for that reason Unknown Value Error has been implemented within that context too. Even for the process which the API request does not perform, Request Error is adapted there also. Due to which it implemented so that this would not get system locked, whereas the system executes in an unbroken way only. This would all have been possible making the time-outs as possible as like Wait Timeout Error or even interrupt on speech and then it all would have come without actually letting the whole process come literally grinding in this very credible situation of timeouts and interrupts readily well accommodable.
- Optimum Performance: This system will cause the whole system to act smart, depending on the amount of usage of its resources, that are made through those processes; hence inputs via the processing line by line, without heavily loading the computing machine. In reality, background processing also maintained proper flows, and nothing of that hitch kind of thing occurs with tasks between recognising translation or synthesis.
VII. CHALLENGES AND CONSIDERATIONS
Although an impressively strong capacity towards real-time speech-to-speech translation, the system is still plaguing with lots of problems that need to be overcome before it works effortlessly and perfectly in all these presented scenarios.
- Accent and Language Processing: Multiple accents such as English. Several languages for instance Hindi and Telugu in addition to many complexities within any accent and respective language make things pretty challenging for the system. In general, speech comprehension is very fast but quite strictly dependent on accent and dialect speaking and thus sometimes misleading or not translated at all. Idiomatic expressions often pose difficulty; this is just because some really long sentences require more complexity of language. Some more developments that could be built from the update would be knowing regional dialects and subtlety continued with a different type of accents and tongue.
- Real Time Performance: The communication is snapped by any sort of delay in processing. The systems are performance-sensitive much for applying toward real time functionalities; however, basically, the system performs the role of real time speech-to-text and real time translation activities, but the issue of latency stands predominantly wherein it allows too elongated sentences to come across as well complicated for processing. Asynchronism or parallel processing, as well perhaps an accelerated version of the model itself, may serve to take these sorts of latency away from the system. Besides, it may able to provide constant input mechanisms that there will be no shock change from speech recognition to translation and finally to speech synthesis.
- Devices Compatibility: The other concerned aspect is how the system interacts with different devices and settings. In fact, it will accept audio with a VB-Cable virtual audio cable device and thus will not have the sound where it should have existed on other systems or may just not work at all on others. Use of USB rather than onboard microphone can further be capitalized for the difference that the system may present in terms of performance. This would make the system highly usable in that sense of dynamically identifying and configuring the most appropriate audio input devices, or even potentially fully obliterating VB-Cable.
- Noise Handling: Background noise is the major problem associated with speech recognition systems. It has the function adjust_for_ambient_noise in trying to compensate. That, at times, isn't enough satisfactorily within a fully noisy environment. There even has been test proven evidence showing high background noises under actual operating conditions have indeed degraded the transcription quality. So, ambient noises reducing algorithms need functionality in other acoustic environments, hence there has to be a need for more than what is currently the sophisticated high-order stuff. Amongst these is the echo canceller or the active noise canceller.
- Translation Accuracy: Most language translation outputs on Google Translate are acceptable but quite unsatisfying if they entail sentences with considerable intricacy or contain particular jargons or phrases. That system would possibly go wrong once in a while to some instances; accuracy of translations will rarely work on translations to or from cultural words, as well as translated phrases or word elements involving idioms. It would depend on further in-depth study with further advancements in the application of neural machine translation models or hybrid techniques, which combines the features of rule-based and statistical translation techniques.
- Voice Naturalness: Another important aspect the users are looking for in voice assistants is the quality of output from TTS. Till date, the service from Google is used by this system in TTS. The voice available from TTS is least natural at all for some regional accents or even less spoken languages. The conversation will be divided because advanced models, such as Wave Net and Tacotron, are developed using deep learning that tries to improve user experience through even more natural speech outputs. Based on the real-time multilingual communication capabilities of different kinds of accents, languages, and environmental conditions, the system would be robust, accurate, and user-friendly. Most of the above-mentioned major issues are unavoidable for developing a sound and scalable real-time accent translation system. Further research has to be carried out to overcome the problems involved in building such a system. There indeed is a concern with regard to speech recognition accuracy, quality of translation, noise-handling, and optimization of this system's performance-all of which require further study for the system to be of that nature to indeed meet the various demands of types of users in real-life practicality
VIII. RESULT
It will allow the users to communicate fluently in other languages and accents once it is implemented. The system applies speech recognition, language translation, and text-to-speech synthesis for it to translate the speech of a user into a target language and then output the translated speech. Regional accents and languages like Hindi, Telugu, and Kannada are accommodated with flexibility in accent and language selection so that the system can reach a large section of its users.
It transcribed speech correctly and translated to the target language or accent. Google's translation API combined with TTS synthesis translated very few errors, and ensured intelligible, clear audio output in the desired voice. The system also performed under different real-time conditions like adjustment to the ambient noise, and the processing of varied speech inputs.
However, some limitations were included in the recognition errors sometimes due to unclear or complex speech and some delays in processing. These are some areas to be optimized while considering speech recognition accuracy and translation efficiency.
The system, in general, performs well as a real-time translation tool and provides a good platform for further improvements and tailoring to decrease latency and enhance accuracy in translation across various languages and accents.
IX. FUTURE SCOPE
The scope areas of the real-time accent translation system have many areas of development and are quite broad indeed. After this technology matures, a few scope areas can be explored in order to bring the system close to efficiency and adaptability for higher applications. Advanced models based on neural networks are added to capture slight expressions in speech as well as variances in pronunciation with possible future extensions targeted at speech recognition accuracy, including diverse accents and regional dialects, and performing well in noise. This is one very important area of development to change the existing speech-to-text approach into a text-to-speech approach. This, in simpler words, refers to the fact that real-time direct processing will come down with the help of direct speech-to-speech translation models and enhance performance. So, this system will respond much better in conversation. It will expand the multi-lingual abilities of the system that supports more languages and dialects; therefore, it will be more accessible worldwide. The quality of translation is improved due to the enhancement of the contextual understanding of the system. The translation considers the context of the conversation, idiomatic expressions, and slang.
Synthesised voice: It is still one of the significant limitations with the TTS systems as of today. Some state-of-art models, such as the Tacotron and Wave Net can be used, thus ensuring more natural or expressive speech thereby making the sound more human. This can be integrated into wearable devices where the person can translate everywhere at any given time, even in emergency conditions where language differences might hinder effective communication. It could also be applied in real-time business communications and customer services or multi-lingual education tools.
Privacy and Security: Because it involves such sensitive information as personal speech and translated content, the agenda would have to be topped by privacy and data security. Future improvements would have to center on security in data transmission, encryption, and mechanisms for user consent to protect users' information.
X. ACKNOWLEDGEMENTS
I would like to warmly thank all the contributors who permitted me to make their effort toward the creation and making of the real-time translation system of accented speech possible. I would like to thank the mentors and advisors who guided me with such valuable wisdom, knowledge, and feedback in the course of this work. They are very well experienced in speech recognition, natural language processing, and machine learning; they set the direction of this work and were highly important in overcoming many difficulties.
I thank all the developers of open-source libraries and frameworks, for which it is not possible to form this system. The key tools of this project were Speech Recognition, a library from which basic tools of this project have been derived; gTTS for text-to-speech conversion; google trans for translation purposes; and pygame for the audio playback system. Without those resources, it is impossible to create a working effective real-time translation system.
Special thanks to the authors and maintainers of the pyaudio library for allowing inclusion of microphone input functionality along with audio device management functionality that was crucial for achieving latency-free audio capture toward real-time application development.
I thank the developers and researchers working in speech recognition and translation APIs, for their job, in fact, allows me to work because it's their work that enables me to be on the front line of this sort of technological advancement; their long time of effort striving for perfection has made it possible toward models of language as well as perfecting the system for recognition purposes.
I would take this chance to thank my family and friends for all that unconditional support, encouragement, and patience in keeping up with this project. They allowed me the freedom to stay on the right path toward attaining those necessary milestones that could eventually help actualize this concept.
I thank all the members of the whole academic and research fraternity, who have now activated this work and given me some precious resources of information and enough knowledge for this presentation about natural language processing onto the real time translation system for the computer.
Not one of our creations but work of all the multiples of peoples towards language technology. Thanks all those who had worked toward this task.
References
[1] \"Accent Conversion using Pre-trained Model and Synthesized Data from Voice Conversion\" by Tuan Nam Nguyen et al. (2022). This paper discusses accent conversion techniques that modify pronunciation patterns and prosody while preserving the speaker\'s voice quality and linguistic content. [2] \"Non-autoregressive Real-time Accent Conversion Model with Voce Cloning\" by Vladimir Nechaev and Sergey Kosyakov (2024). This study presents a model for real-time accent conversion with voice cloning capabilities, suitable for multi-user communication scenarios. [3] \"Accent Conversion with Articulatory Representations\" by Yashish M. Siriwardena et al. (2024). This research introduces the use of articulatory speech representations to enhance accent conversion effectiveness. [4] \"A Survey of Voice Translation Methodologies\". This paper surveys recent advances in speech engineering, focusing on recognition, translation, and synthesis in voice-to-voice translation devices. [5] \"Real-Time Speech Translation with Python\". This project presents the development of a real-time speech translation system using Python and Google\'s Translation library, facilitating seamless communication across different languages. [6] \"Power of Babel: The Evolution of Real-Time Translation Features\" by Nathan Eddy (2024). This article discusses how artificial intelligence has enhanced real-time translation features, improving accuracy and facilitating cross-cultural communication. [7] \"Real-Time Accent Translation & Speech Understanding\" by Sanas. This source provides insights into Sanas\'s patented real-time accent translation technology, which utilizes speech-to-speech AI processing and advanced neural networks. [8] \"This 6-Million-Dollar AI Changes Accents as You Speak\". This article explores an AI algorithm capable of shifting English accents, highlighting the practical applications of accent translation technology.
Copyright
Copyright © 2025 V A Mayavathi, Ballani Vignesh, V. Hemavathi, Aditi Gupta, K. Gnanendra Varma, Dr. Galiveeti Poornima. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66549
Publish Date : 2025-01-16
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online